If you’ve ever wondered how Netflix knows exactly what show to recommend next, or how your phone’s keyboard seems to read your mind well, friend, you’ve already bumped into AI doing its thing. But how does it actually learn all of that? That’s exactly what we’re unpacking today.
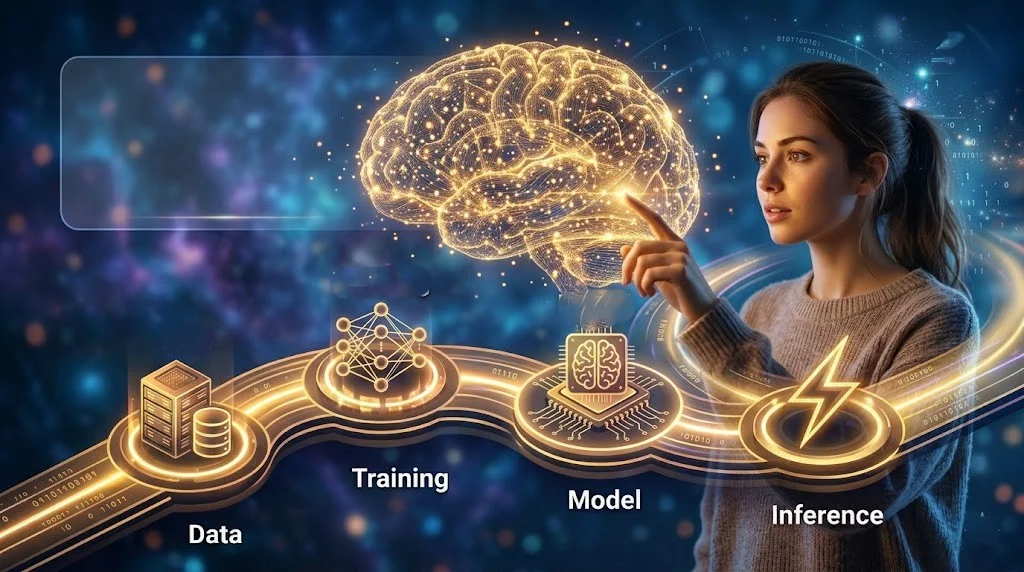
Whether you’re completely new to AI or just someone who keeps hearing the buzzwords and wants to finally get it this one’s for you. No jargon overload. No PhD required. Just a friendly, honest breakdown of the four steps in the AI learning journey: Data → Training → Model → Inference.
Let’s go.
Why This Even Matters (And Why You Should Care)
AI is reshaping everything the way we work, shop, communicate, and create. But for most people, it still feels like magic. And honestly? That’s not great. When you don’t understand something that’s running in the background of your life, it can feel intimidating or even a little scary.
The good news: AI isn’t magic. It’s a process. A very cool, very learnable process with exactly four core steps. Once you get this, you’ll see the world a little differently and that’s a genuinely good feeling.
Step 1: Data-The Raw Ingredient Everything Starts With
Think of data as the life experience of an AI. Just like you learned to speak by hearing thousands of conversations around you, an AI learns by consuming massive amounts of information.
This data can be text, images, audio, video, numbers pretty much anything you can capture and store digitally. A chatbot learns from billions of sentences. A medical AI learns from thousands of X-rays. A recommendation engine learns from millions of user clicks and watch histories.
But here’s the thing people often skip over: the quality of data matters enormously. If you feed an AI biased, incomplete, or messy data, it’s going to give you biased, incomplete, or messy results. Garbage in, garbage out it’s a cliché in tech circles for a reason.
What happens in this step:
- Raw data is collected from various sources
- It gets cleaned (removing errors, duplicates, irrelevant bits)
- It’s organized and labeled so the AI knows what it’s looking at
- It’s split into training data, validation data, and test data
Real example: When training an AI to detect spam emails, engineers fed it millions of emails labeled “spam” or “not spam.” The more examples it got, the better it learned to tell the difference.
Step 2: Training-Where the Real Magic Happens
This is where an AI goes from clueless to capable. Training is the actual learning phase, and it’s fascinating once you understand what’s going on under the hood.
During training, the AI looks at all those examples from Step 1 and tries to find patterns. It makes predictions, checks if it got things right, and then adjusts itself. Over and over and over again. Sometimes millions of times.
This is done through something called a neural network loosely inspired by how the human brain works. The network has layers of interconnected nodes (kind of like neurons), and during training, the connections between them get stronger or weaker based on what the AI gets right or wrong.
There’s a mathematical process called backpropagation that’s doing the heavy lifting here. Every time the AI makes a mistake, the error signal travels backward through the network, tweaking the weights (connection strengths) to get a better result next time.
Think of it like this: Imagine you’re learning to throw a basketball. The first few throws are terrible. But you get feedback too far left, not enough arc and slowly your muscle memory kicks in. Training an AI is that same loop, just running at computer speed.
Training can take hours, days, or even weeks, depending on how complex the task is. Training a large language model (like the kind behind AI chatbots) can require thousands of specialized computer chips running simultaneously.
Step 3: Model-The Brain Gets Saved
Once training is done, what you have is called a model. This is basically the AI’s learned knowledge, packaged up and saved as a file (or set of files).
Think of the model as the brain after school. The AI has gone through all that training, figured out the patterns, and now that knowledge is crystallized into something usable. You don’t need to train it again every time you want to use it you just load up the model and go.
The model contains all those fine-tuned weights and connections from training. It knows, for example, that certain patterns of words usually mean someone is expressing frustration, or that a particular set of pixels in an image usually means there’s a dog in the frame.
Key things to know about models:
- They vary wildly in size from tiny models that run on your phone, to enormous ones that need entire data centers
- A model’s performance is evaluated using the “test data” that was set aside in Step 1
- Models can be retrained or fine-tuned if they need updating (more on that in the feedback loop below)
- Models are often shared publicly (like Meta’s open-source Llama models) or kept proprietary by companies
This step is also where a lot of the interesting AI development conversations happen. Researchers are constantly working on making models smaller without sacrificing performance, more efficient, less biased, and safer to deploy.
Step 4: Inference The AI Finally Does Its Job
Here’s where all that hard work pays off. Inference is when the trained model meets the real world it’s when an AI actually uses what it learned to answer questions, make predictions, or take actions.
Every time you type a question into a chatbot and it responds? That’s inference. Every time Google auto-completes your search? Inference. Every time your phone unlocks using your face? Inference.
The model takes new input (something it hasn’t seen before), runs it through all those learned layers of knowledge, and produces an output. And it does this in milliseconds.
What’s impressive about inference is how well-trained models generalize meaning they can handle situations they were never directly trained on. That’s the real marker of intelligence, artificial or otherwise.
Inference can happen:
- In the cloud (the heavy processing happens on a server somewhere)
- On your device (called “on-device” or “edge” inference used in phones, smart speakers)
- In real-time (like voice assistants responding instantly)
- In batches (like an AI processing thousands of documents overnight)
As models get smaller and more efficient, more inference is moving onto devices directly which means faster responses and better privacy, since your data doesn’t have to leave your phone.
The Bonus: The Feedback Loop That Makes AI Get Smarter Over Time
Here’s something the simple “four steps” framing sometimes leaves out the journey doesn’t really end at inference. Good AI systems have a feedback loop built in.
When a model makes mistakes in the real world, or when users correct it, that information becomes new training data. The model gets updated, retrained, and improved. This is why your autocorrect gets better the more you use it, and why recommendation systems feel scarily accurate after a while.
It’s a continuous cycle: Data → Training → Model → Inference → Feedback → Better Data → Better Training and so on
Quick Recap: Your Cheat Sheet
| Step | What It Is | Real-World Analogy |
|---|---|---|
| Data | Collecting and organizing examples | Reading thousands of books before writing one |
| Training | AI finds patterns and adjusts itself | A student studying and practicing |
| Model | The learned knowledge, saved and packaged | A finished exam paper- everything is locked in |
| Inference | Using the model on new real-world input | Applying your knowledge in a job interview |
FAQs:
Q: How much data does an AI actually need to learn?
It depends on the task. Simple tasks (like detecting whether an email is spam) might need thousands of examples. Large language models are trained on hundreds of billions of words essentially a huge chunk of the internet. The rule of thumb: more diverse, high-quality data usually means better results.
Q: Can an AI learn from just one example?
Standard training methods need lots of examples, but researchers have developed “few-shot” and “one-shot” learning techniques that let models generalize from very limited data. It’s an active area of research and honestly, a really exciting one.
Q: What’s the difference between AI, machine learning, and deep learning?
Think of them as nested circles. AI is the big umbrella any system that mimics intelligence. Machine learning is a subset where systems learn from data (rather than being explicitly programmed). Deep learning is a subset of machine learning that uses large neural networks with many layers and it’s what powers most of today’s impressive AI breakthroughs.
Q: How long does it take to train an AI model?
Anywhere from a few minutes (for simple models on small datasets) to several months (for massive language models trained on supercomputing clusters). Training GPT-4-scale models reportedly cost tens of millions of dollars just in computing time.
Final Thoughts: You’ve Got This
The four steps in the AI learning journey- data, training, model, and inference aren’t some mysterious black box anymore. They’re a process, and now you understand it.
What’s really exciting is that we’re still in the early days of all of this. The models are getting better, the data pipelines are getting smarter, and inference is happening on smaller and faster devices every year. Understanding these fundamentals puts you in a genuinely good position whether you want to work in AI, use AI tools more effectively, or just have smarter conversations about where the technology is headed.
So the next time someone brings up AI at a dinner table and it feels like everyone’s talking in circles, you can quietly nod and think to yourself: yeah, I know how that works.
That’s a pretty good place to be.

Sushil Kumar is a results-focused digital marketer specializing in SEO, content planning, and AI-powered workflows. His platform offers easy-to-use AI prompts for creating professional photos.





